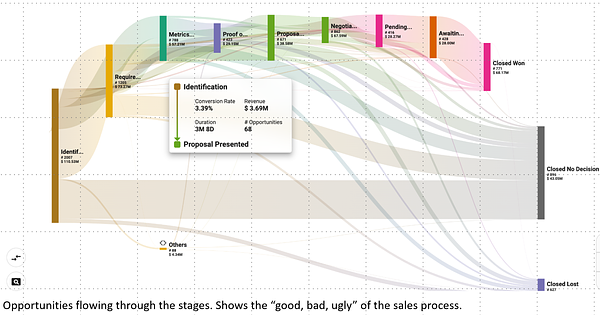
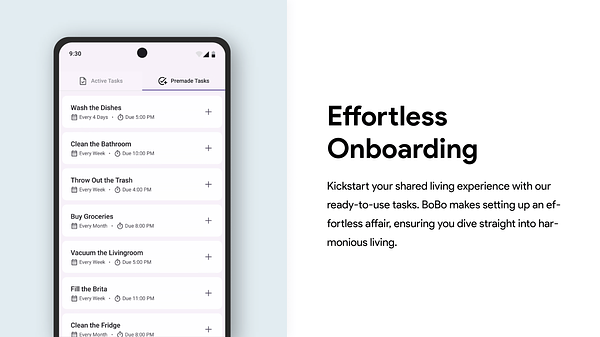
Austin, Texas, pulsates with a unique blend of musical rhythms and innovative entrepreneurship. Renowned as the “Live Music Capital of the World,” its streets echo with diverse melodies ranging from indie rock to country. Simultaneously, Austin’s dynamic startup scene is booming, emerging as a hotbed for tech innovation and creative business ventures. Here are a few of the startups in the Austin scene. To hear the voice of the Austin startup community, read the Austin Startups Blog.



.png)
%201.png)
.jpeg)










.png)


